A developer makes a small change to a shopping app before leaving work. The buttons look cleaner. The chatbot sounds more helpful. By the next morning, the app has already been tried by dozens of different users, each with a different need.
That is the promise behind our new prototype for testing interactive software with simulated users.
The Problem: One App, Many Users
Modern apps rarely have one simple audience. A movie recommender may work well for someone who wants a Friday-night comedy, but fail a filmmaker looking for Korean-American stories with bilingual dialogue. A beauty chatbot may satisfy a casual shopper, but disappoint a nail artist who needs professional, non-toxic polish. Real user studies can reveal these gaps. They are also slow, expensive, and hard to repeat after every design change.
A Wind Tunnel for Software
Our prototype gives developers a faster way to look for those gaps early. It starts with a library of richly described user profiles, one that can be plugged into the system. Each profile sketches a possible user: their work, habits, budget, preferences, and the constraints they may bring to a task. A language model then uses one of these profiles to act as that user. It can answer a survey, chat with a recommendation system, or browse a web store. Afterward, the system returns a record of the interaction: what the user tried to do, where the app helped, and where it fell short.
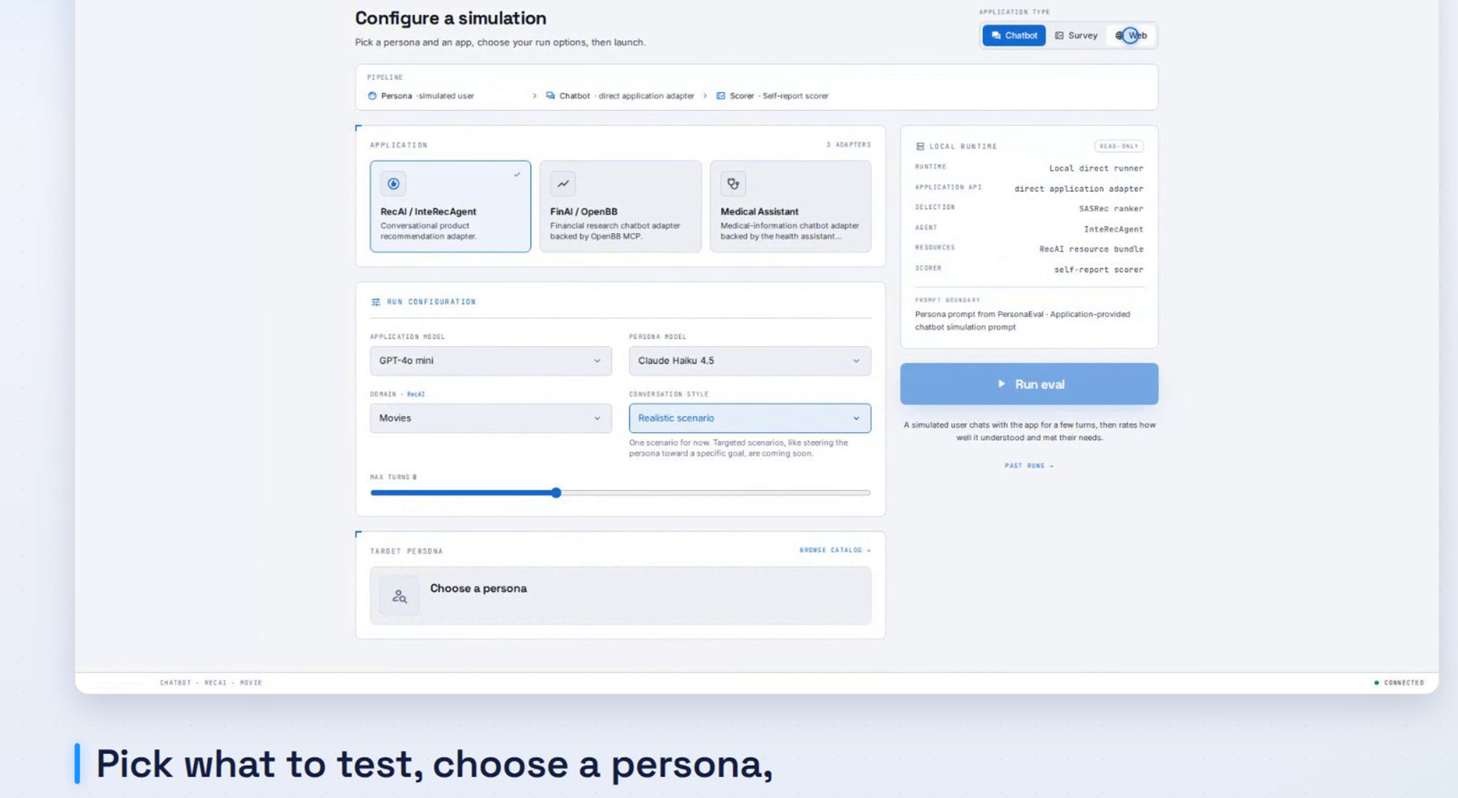
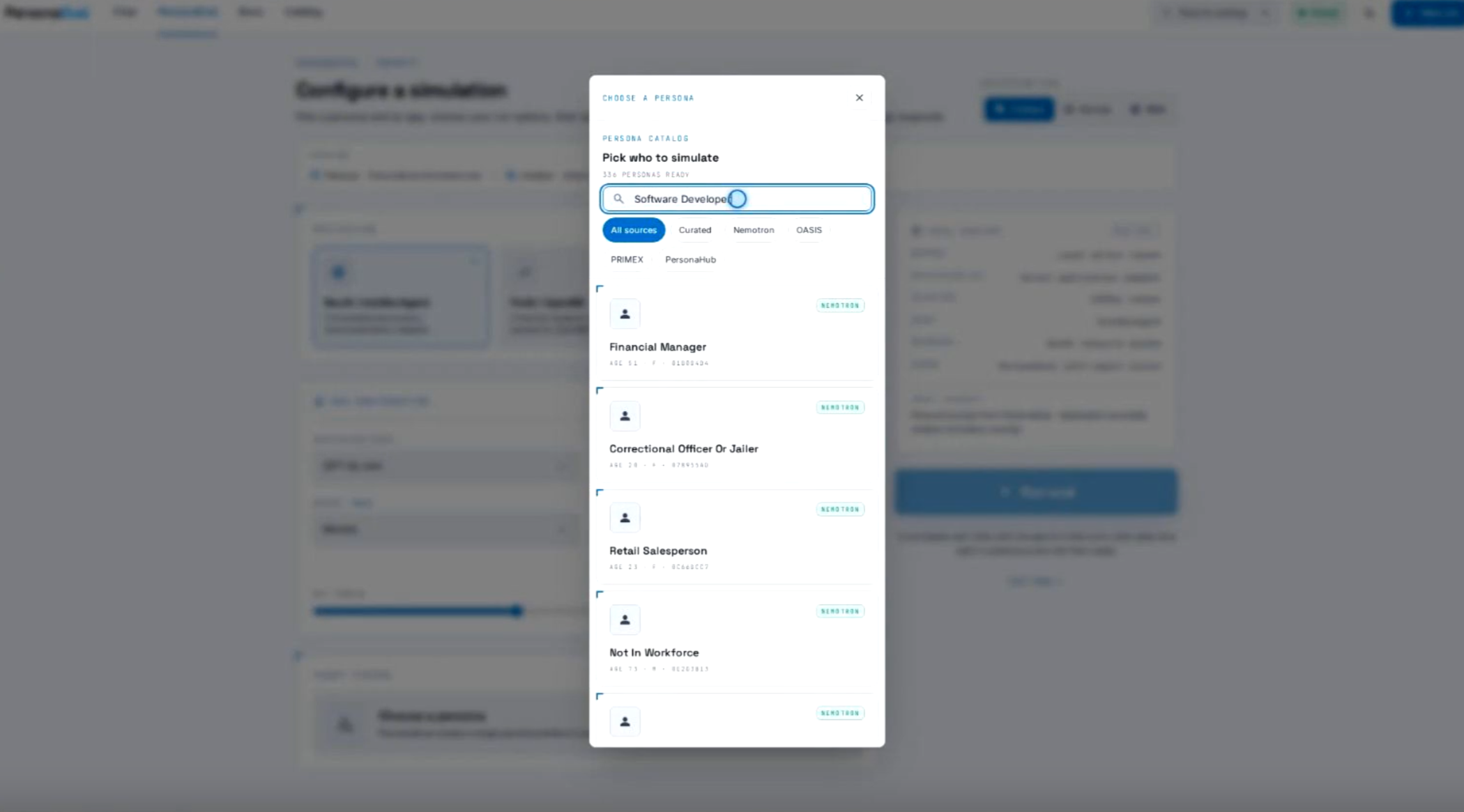
A useful way to think about the system is a wind tunnel. Engineers still need real flight tests, but they first use controlled air to see where a design shakes. This prototype does the same for software. It does not prove how every real person will behave. It helps teams find weak spots before asking real people to spend their time.
Testing at Scale
We tested the system on three kinds of applications: surveys, chatbots, and a web shopping task. For each application, the system selected fifty relevant user profiles and let them interact with the software. The most interesting results were not the average scores. They were the differences between user groups.
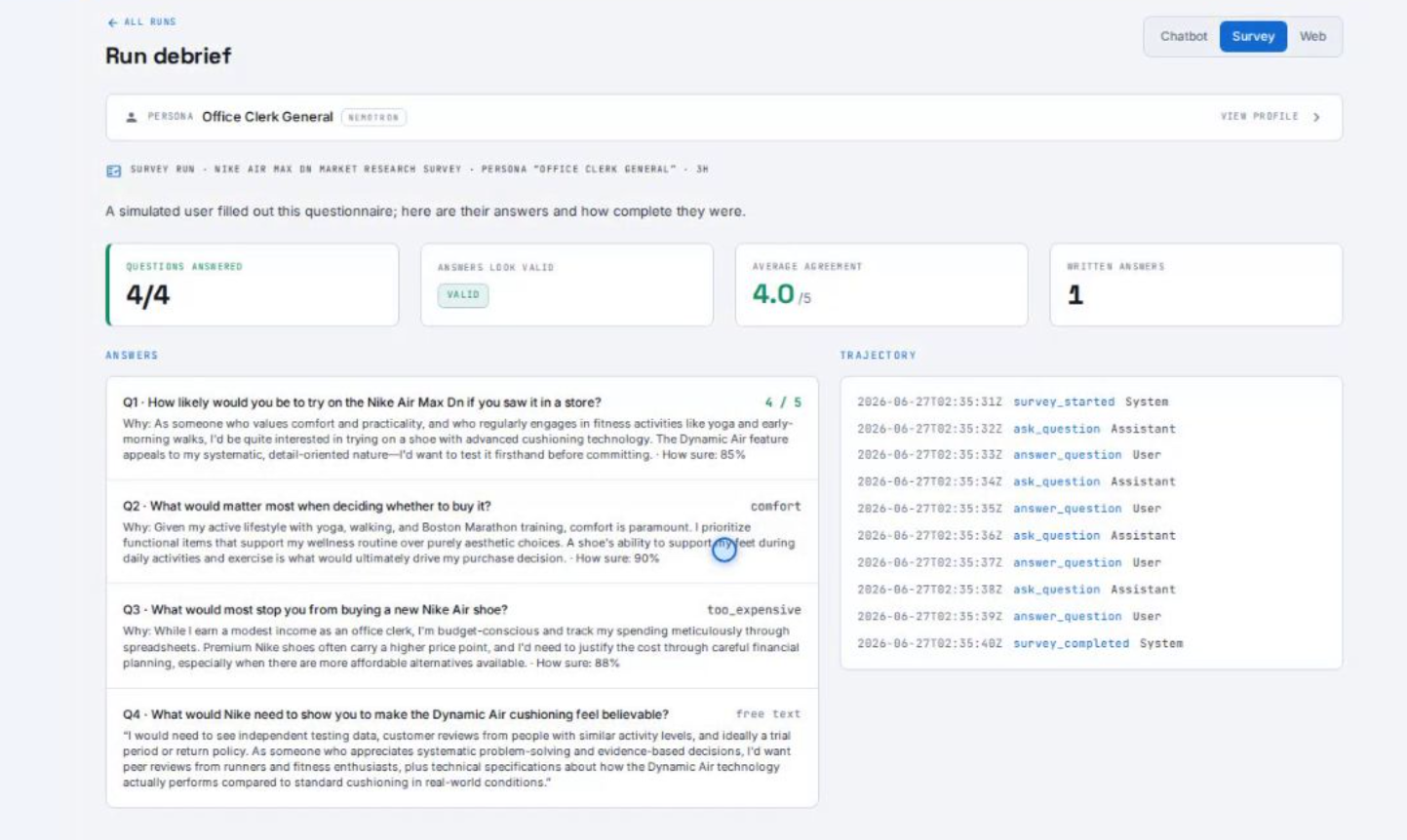
In one beauty-product test, a simulated nail professional asked for vivid, non-toxic nail polish. The recommender offered removers, top coats, and cleaning products. That was not a vague failure. It showed exactly where the system misunderstood the user's goal.
Beyond the Average User
This matters because "the average user" is often a convenient fiction. A product that works for beginners may fail experts. A tool that helps casual shoppers may frustrate professionals. Simulated testing could let teams study these differences earlier, cheaper, and more often.
See the Prototype in Action
Watch how the simulated user testing framework evaluates an interactive application in real-time.
The system demonstrates:
- Multiple user profiles interacting with the same app
- Real-time feedback collection and analysis
- Identification of user experience gaps across different personas
- Actionable insights for product teams
This wind tunnel approach lets developers find and fix issues before they reach real users.
The Open Question
The open question is how closely simulated users match real ones. If future work can calibrate these rehearsals against human studies, app testing may become less like guessing and more like listening.
A technical write-up will be shared when the review process allows.